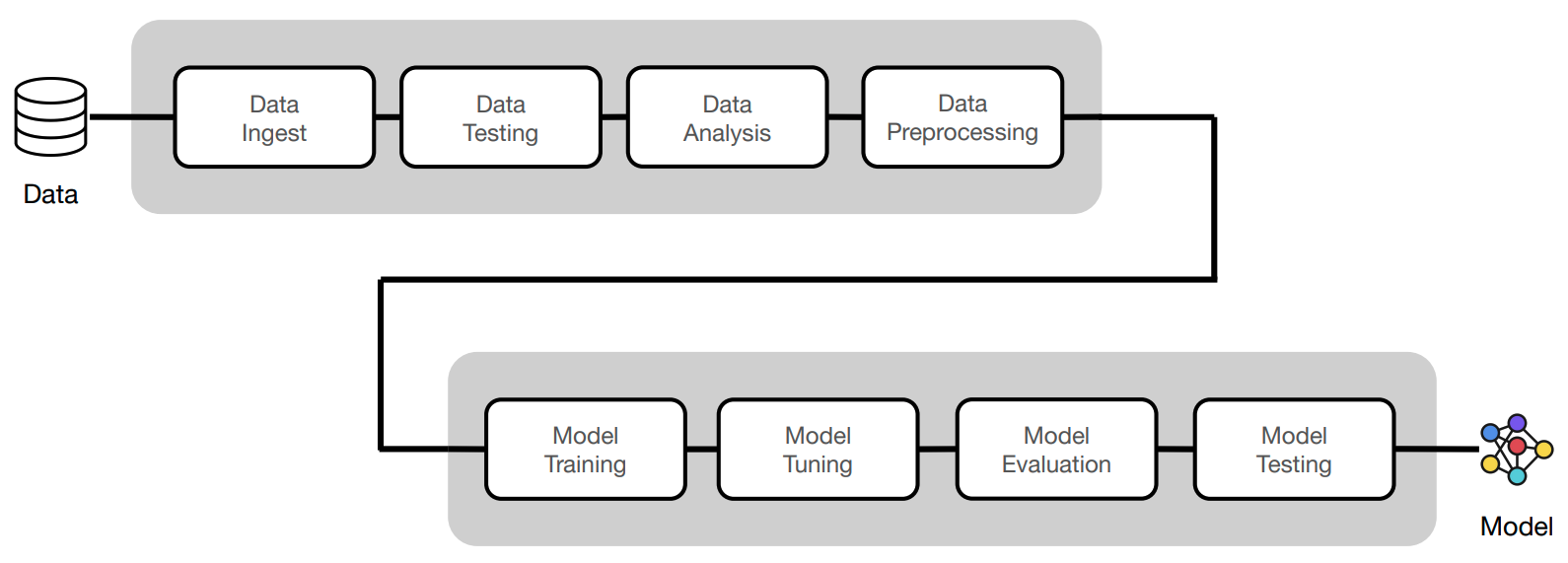
- training:
- access to training data and testing (holdout) data.
- was there sampling of any kind applied to create this dataset?
- are we introducing any data leaks?
- production:
- how can we trust that this stream only has data that is consistent with what we have historically seen?
| Assumption | Reality | Reason |
|---|---|---|
| All of our incoming data is only machine learning related (no spam). | We would need a filter to remove spam content that's not ML related. | To simplify our ML task, we will assume all the data is ML content. |
Our task
Labeling
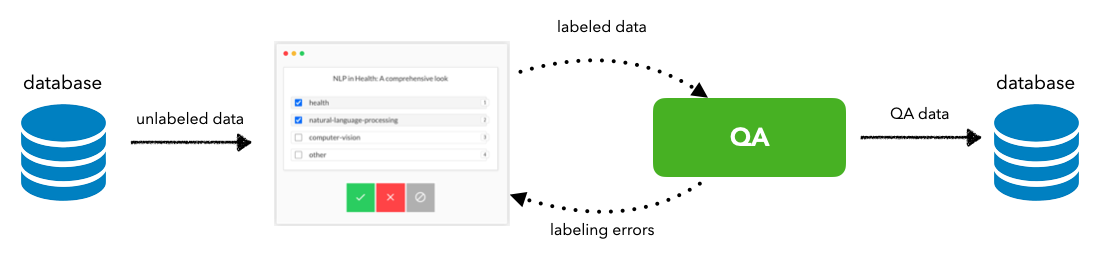
Our task
Labels: categories of machine learning (for simplification, we've restricted the label space to the following tags: natural-language-processing, computer-vision, mlops and other).
Features: text features (title and description) that describe the content.
| Assumption | Reality | Reason |
|---|---|---|
| Content can only belong to one category (multiclass). | Content can belong to more than one category (multilabel). | For simplicity and many libraries don't support or complicate multilabel scenarios. |
Metrics
One of the hardest challenges with ML systems is tying our core objectives, many of which may be qualitative, with quantitative metrics that our model can optimize towards.
Offline evaluation
Offline evaluation requires a gold standard holdout dataset that we can use to benchmark all of our models.
Our task
We'll be using this holdout dataset for offline evaluation. We'll also be creating slices of data that we want to evaluate in isolation.
Online evaluation
Online evaluation ensures that our model continues to perform well in production and can be performed using labels or, in the event we don't readily have labels, proxy signals.
Our task
- manually label a subset of incoming data to evaluate periodically.
- asking the initial set of users viewing a newly categorized content if it's correctly classified.
- allow users to report misclassified content by our model.
It's important that we measure real-time performance before committing to replace our existing version of the system.
- Internal canary rollout, monitoring for proxy/actual performance, etc.
- Rollout to the larger internal team for more feedback.
- A/B rollout to a subset of the population to better understand UX, utility, etc.
Modeling
While the specific methodology we employ can differ based on the problem, there are core principles we always want to follow:
- End-to-end utility: the end result from every iteration should deliver minimum end-to-end utility so that we can benchmark iterations against each other and plug-and-play with the system.
- Manual before ML: try to see how well a simple rule-based system performs before moving onto more complex ones.
- Augment vs. automate: allow the system to supplement the decision making process as opposed to making the actual decision.
- Internal vs. external: not all early releases have to be end-user facing. We can use early versions for internal validation, feedback, data collection, etc.
- Thorough: every approach needs to be well tested (code, data + models) and evaluated, so we can objectively benchmark different approaches.
Feedback
How do we receive feedback on our system and incorporate it into the next iteration? This can involve both human-in-the-loop feedback as well as automatic feedback via monitoring, etc.
Always return to the value proposition
While it's important to iterate and optimize on our models, it's even more important to ensure that our ML systems are actually making an impact. We need to constantly engage with our users to iterate on why our ML system exists and how it can be made better.


Comments
Post a Comment